
About Crawlkit
Crawlkit is your all-in-one solution for turning the web into a reliable, structured data source. It's a powerful web data extraction platform built specifically for developers and data teams who are tired of the headaches that come with traditional web scraping. Instead of spending weeks or months building a fragile system that fights against anti-bot protections, rotating proxies, and JavaScript-heavy sites, Crawlkit provides a single, simple API that handles all that complexity for you. You just send a request with a URL, and Crawlkit manages everything from proxy rotation and headless browser rendering to automatic retries and bypassing blocks, delivering clean, parsed data directly to your application. It's designed for anyone who needs scalable access to web data—whether you're monitoring competitor prices, tracking news, gathering public datasets, or enriching your CRM—without the operational nightmare. With industry-leading success rates, transparent pricing, and a developer-first approach, Crawlkit lets you focus entirely on using data, not on the exhausting task of collecting it.
Features of Crawlkit
One API for Every Data Source
Crawlkit consolidates access to numerous platforms into one unified interface. With a single API call, you can extract structured data from websites, social media platforms like LinkedIn and Instagram, and app stores (Play Store, App Store). This eliminates the need to juggle multiple specialized tools or write separate scrapers for each site, saving you significant development time and maintenance effort.
Built-In Anti-Bot Bypass
The platform automatically handles the biggest challenges in modern web scraping. It manages proxy rotation, executes JavaScript in headless browsers, performs automatic retries, and employs techniques to bypass common blocks and rate limits. This means you get a consistently high success rate when fetching data, without having to build or troubleshoot this complex infrastructure yourself.
Transparent, Credit-Based Pricing
Crawlkit uses a simple, pay-as-you-go credit system. Each API endpoint costs a fixed number of credits (e.g., 1 credit for an Instagram profile, 2 for a LinkedIn profile). Credits never expire, there are no monthly commitments or rate limits, and you only pay for successful requests. This model provides complete cost predictability and scales affordably with volume discounts.
Developer-First SDK & Simplicity
Crawlkit is built for seamless integration. It offers an official SDK for Node.js and works as a simple HTTP API that can be called from any programming language or platform. The setup is straightforward: install the SDK, use your API key, and start making requests. This design ensures there's no vendor lock-in and you can easily fit Crawlkit into your existing workflows and automation tools.
Use Cases of Crawlkit
CRM and Lead Enrichment
Automatically enrich contact profiles in your Customer Relationship Management (CRM) system with fresh, professional data. By pulling structured information from LinkedIn, such as job titles, current company, experience, and skills, you can build richer lead profiles for your sales team without any manual data entry, making outreach more personalized and effective.
Competitive Intelligence and Market Research
Track your competitors' digital footprint effortlessly. Monitor their Instagram for follower growth and engagement rates, scrape their app store reviews for user sentiment, or track pricing changes on their e-commerce site. Crawlkit provides the reliable data pipeline you need to stay informed and make strategic business decisions based on real-time market information.
App Store Review Analysis
Gather all user reviews for your app or your competitors' apps from the Google Play Store and Apple App Store. With clean, structured data on ratings, review text, and dates, you can perform sentiment analysis, identify common user complaints or feature requests, and gain valuable insights to guide your product development and marketing strategies.
Social Media Growth Tracking
Build dashboards to monitor social media performance over time. Schedule regular calls to Crawlkit's Instagram API to track follower counts, post engagement metrics, and profile details for your brand or competitors. This allows you to measure campaign effectiveness, benchmark performance, and understand trends in your industry's social media landscape.
Frequently Asked Questions
How do I get started with Crawlkit?
Getting started is simple and free. First, sign up on the Crawlkit website to receive 100 free credits. Then, find your unique API key in your account dashboard. You can immediately test endpoints using the provided Playground in your browser or install the official Node.js SDK (npm install @crawlkit-sh/sdk) to make your first API call from code in just a few minutes.
What happens if a request fails?
Crawlkit operates on a "refund on failure" policy. If an API request fails to return the requested data (due to a site block, network error, etc.), the credits used for that attempt are automatically refunded to your account. You only pay for successful requests that deliver complete, structured data to your application.
Can I use Crawlkit with programming languages other than Node.js?
Absolutely. While Crawlkit provides a convenient SDK for Node.js, at its core it is a standard HTTP REST API. This means you can use it with any programming language that can make HTTP requests, such as Python, Go, Ruby, PHP, or Java. Simply send a POST request with the correct endpoint and your API key in the headers.
Do you support a website or platform that isn't listed?
Yes, Crawlkit is continually expanding its supported platforms. If you need to extract data from a specific website, social platform, or service that isn't currently listed as a dedicated endpoint, you can contact their team directly. They offer custom development and are often willing to build a new, reliable API endpoint to meet your specific data needs.
Explore more in this category:
Similar to Crawlkit
InContekst
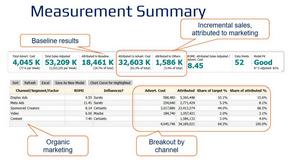
Decision support framework for high consideration businesses with mix of online and offline channels, content-rich sites, and long customer journeys.

SeeCalc
SeeCalc is built and maintained by a single developer passionate about making marketing math fast, transparent, and free.
EnsembleData
EnsembleData provides real-time social media data APIs to effortlessly scrape and analyze posts, profiles, and trends for your business needs.

Shadcn Examples
Discover ready-to-use Shadcn UI blocks and examples to quickly build beautiful React and Tailwind web apps.
Subiq
Subiq helps small teams effortlessly manage their SaaS subscriptions, saving money and preventing wasted spend on unused tools.