Agenta
Agenta is an open-source platform that helps teams build and manage reliable AI apps together.
Visit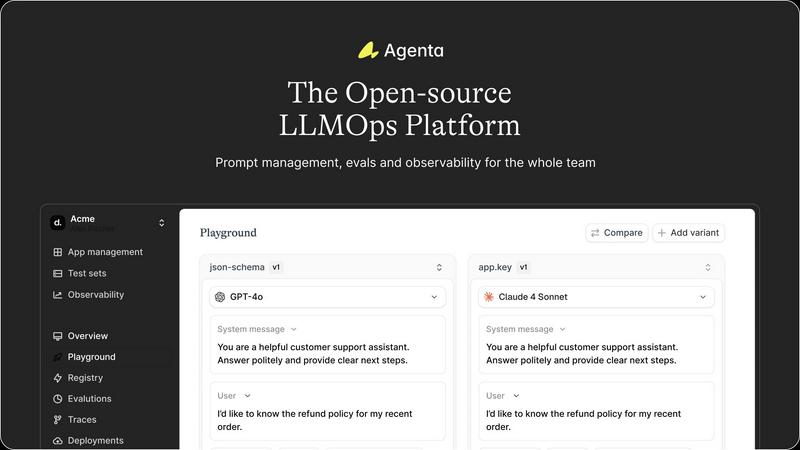
About Agenta
Agenta is your friendly, open-source platform designed to help teams build and ship reliable AI applications powered by large language models (LLMs). If you've ever felt frustrated by the unpredictable nature of LLMs, with prompts scattered everywhere and debugging feeling like guesswork, Agenta is here to help. It's built for the whole team-developers, product managers, and subject matter experts-to collaborate seamlessly. The platform acts as your single source of truth, centralizing the entire LLM development workflow. You can experiment with different prompts and models, run automated evaluations to replace gut feelings with hard evidence, and observe your live applications to quickly pinpoint issues. By bringing everyone together and providing the right tools, Agenta transforms chaotic, siloed processes into a structured, efficient practice known as LLMOps, helping you move from experimentation to production with confidence. Whether you're a developer tired of manual testing or a product manager needing visibility into AI performance, Agenta provides the integrated infrastructure for prompt management, evaluation, and observability you need to succeed.
Features of Agenta
Unified Playground
Agenta provides a unified playground where you can safely experiment with different prompts and models side-by-side in one central interface. This eliminates the need to juggle multiple tools or windows. Found an error in production? You can easily save it to a test set and use it directly in the playground to debug and iterate, making prompt engineering a collaborative and data-driven process.
Automated Evaluation
Replace guesswork with evidence using Agenta's systematic evaluation framework. You can create automated tests to validate every change to your LLM application. The platform supports any evaluator you need, including LLM-as-a-judge, built-in metrics, or your own custom code. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, to pinpoint exactly where things go right or wrong.
Comprehensive Observability
Gain full visibility into your live AI applications with detailed tracing for every request. This allows you to quickly debug systems and find the exact failure points when things go wrong. You can annotate traces with your team or gather feedback from users directly within the platform. Any trace can be turned into a test case with a single click, creating a powerful feedback loop.
Team Collaboration Hub
Agenta breaks down silos by providing a shared workspace for your entire team. It offers a safe, no-code UI for domain experts to edit and experiment with prompts. Product managers and experts can run evaluations and compare experiments directly from the interface, while developers work via the full-featured API. This parity between UI and API workflows brings everyone into one cohesive development process.
Use Cases of Agenta
Streamlining Prompt Engineering Workflows
Teams can centralize their prompt development, moving away from scattered documents in Slack, Google Sheets, and emails. With version history and side-by-side comparison, developers and domain experts can collaboratively iterate on prompts, test them with real data, and track all changes systematically, leading to more reliable and performant prompts.
Running Rigorous LLM Application Tests
Before deploying any change, teams can establish a rigorous evaluation process. They can build test sets from production errors, use automated evaluators (like LLM judges) to score outputs, and integrate human feedback from experts. This ensures every update is backed by data, preventing performance regressions and "vibe testing" before going to production.
Debugging Complex AI Agents in Production
When a multi-step AI agent behaves unexpectedly in a live environment, Agenta's observability tools shine. Engineers can trace every step of the agent's reasoning chain, annotate where failures occurred, and immediately use those problematic traces to create new test cases. This turns painful guesswork into a structured debugging workflow.
Enabling Cross-Functional AI Development
Agenta empowers non-technical team members to contribute directly to the AI development lifecycle. Product managers can define evaluation criteria and run tests, while subject matter experts can tweak prompts in a safe UI environment without writing code. This collaboration accelerates iteration and ensures the final product aligns with business and domain expertise.
Frequently Asked Questions
Is Agenta really open-source?
Yes, Agenta is fully open-source. You can dive into the code on GitHub, contribute to the project, and self-host the platform. This gives you full control over your data and infrastructure while benefiting from a tool built and vetted by a community of hundreds of AI builders.
What AI frameworks does Agenta work with?
Agenta is designed to be flexible and model-agnostic. It seamlessly integrates with popular frameworks like LangChain and LlamaIndex, and works with models from any provider, including OpenAI, Anthropic, and open-source models. This prevents vendor lock-in and lets you use the best model for each task.
How does Agenta help with collaboration?
Agenta provides a single platform that serves both technical and non-technical team members. It offers a no-code UI for experts to edit prompts and run evaluations, while providing a full API for developers. This shared "source of truth" for prompts, tests, and traces ensures everyone is aligned and can contribute effectively.
Can I use Agenta to monitor live applications?
Absolutely. Agenta's observability features allow you to trace every request to your live LLM application. You can monitor performance, detect regressions with online evaluations, and gather user feedback on specific outputs. This continuous oversight is crucial for maintaining and improving reliable AI systems in production.
Explore more in this category:
Similar to Agenta
Headless Domains
Headless Domains provides AI agents with secure, verifiable identities for trust in digital interactions and transactions.