Friendli Engine
About Friendli Engine
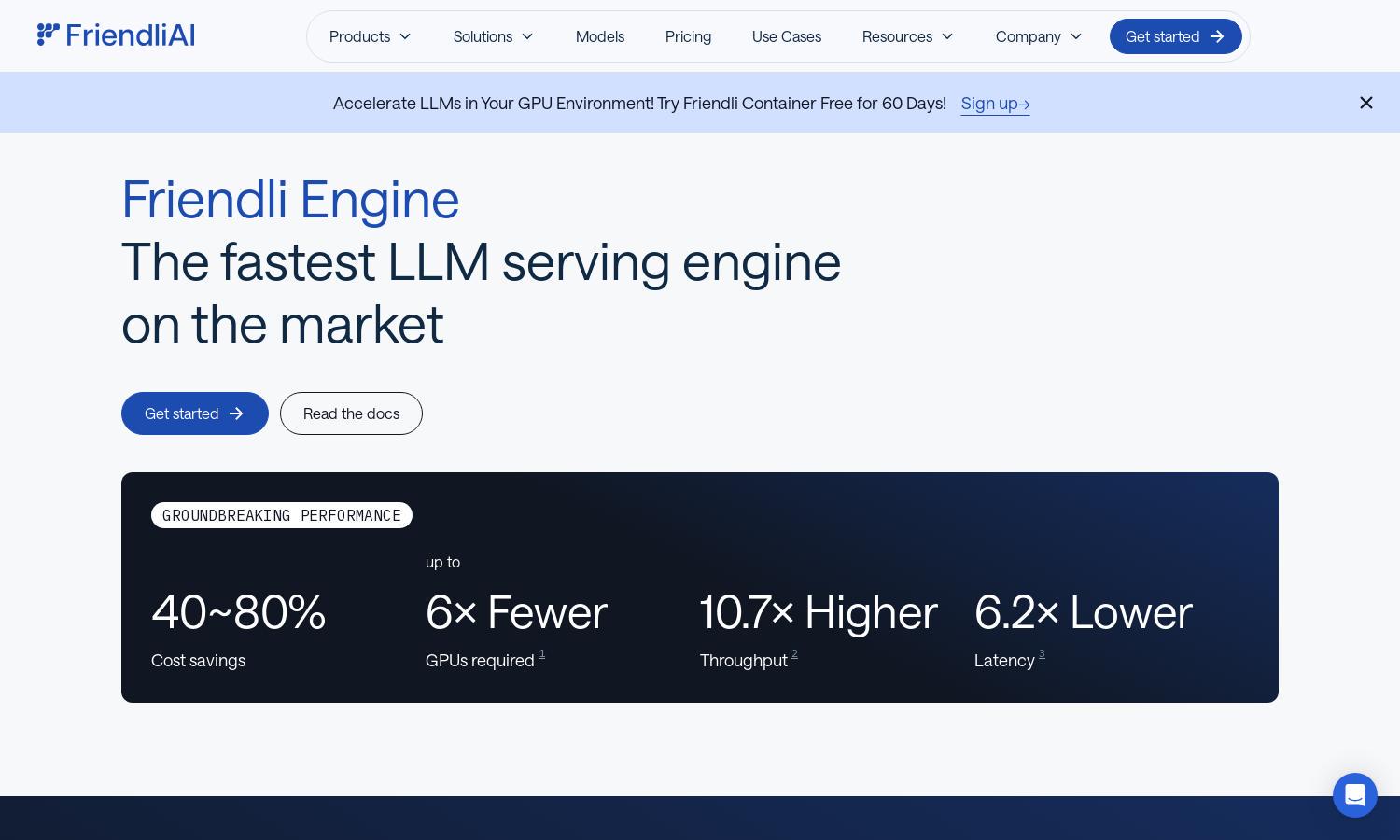
Friendli Engine is a powerful platform designed for businesses needing fast and affordable LLM inference. Its innovative technologies, including Iteration batching and Friendli TCache, ensure high throughput and low latency. Friendli Engine simplifies the use of generative AI, making it accessible for various applications while driving down costs.
Friendli Engine offers flexible pricing plans catering to different business needs, allowing users to choose from basic to premium subscriptions. Each tier provides additional features, enhanced performance, and customer support options. By upgrading, users can unlock advanced capabilities and drive more significant savings in LLM inference costs.
The user interface of Friendli Engine is intuitively designed, making navigation seamless. The layout provides quick access to features like model deployment and real-time monitoring. With user-friendly controls and responsive design, Friendli Engine enhances the overall experience, ensuring users can efficiently manage their LLM inference tasks.
How Friendli Engine works
Users begin by signing up on Friendli Engine, where they can choose from various deployment options. The onboarding process is straightforward and includes guided setup for different generative AI models. Once set up, users can easily navigate the dashboard, manage their models, run inference tasks efficiently, and access analytical tools for performance tracking.
Key Features for Friendli Engine
Multi-LoRA Serving
Friendli Engine supports Multi-LoRA serving on a single GPU, dramatically enhancing LLM customization. This unique capability allows users to deploy multiple LoRA models simultaneously, optimizing resource usage and making LLM customization more accessible and efficient without sacrificing performance.
Iteration Batching
Iteration batching is a groundbreaking feature of Friendli Engine that significantly boosts LLM inference throughput. By handling multiple concurrent generation requests through continuous batching, this function achieves impressive performance gains, making LLM serving more efficient and responsive for users needing high output under tight latency constraints.
Speculative Decoding
Speculative decoding is a unique feature of Friendli Engine that accelerates inference by predicting future tokens while generating current ones. This innovative approach enhances overall response times, ensuring consistent outputs, making Friendli Engine an ideal choice for users requiring fast and reliable generative AI deployments.
You may also like: